publications
The symbol * denotes shared first authorship; the order of the authors is alphabetical in these cases.
2025
- NeurIPS
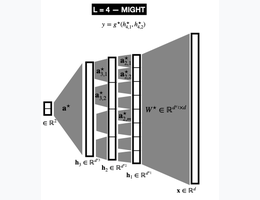 The Computational Advantage of Depth: Learning High-Dimensional Hierarchical Functions with Gradient DescentIn Advances in Neural Information Processing Systems (Spotlight, Notable top 3.5%) , 2025
The Computational Advantage of Depth: Learning High-Dimensional Hierarchical Functions with Gradient DescentIn Advances in Neural Information Processing Systems (Spotlight, Notable top 3.5%) , 2025 - AISTATS
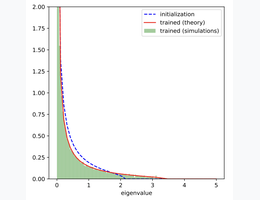 A Random Matrix Theory Perspective on the Spectrum of Learned Features and Asymptotic Generalization CapabilitiesIn Artificial Intelligence and Statistics (Oral, Notable top 2%) , 2025
A Random Matrix Theory Perspective on the Spectrum of Learned Features and Asymptotic Generalization CapabilitiesIn Artificial Intelligence and Statistics (Oral, Notable top 2%) , 2025
2024
- preprint
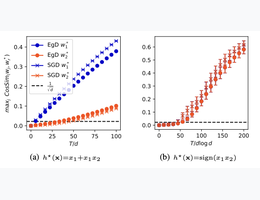 Repetita iuvant: Data repetition allows sgd to learn high-dimensional multi-index functions2024
Repetita iuvant: Data repetition allows sgd to learn high-dimensional multi-index functions2024